Airflow Concepts
Why use Airflow
Run tasks on a regular schedule
For example the bentham app airflow pipeline runs daily and processes prisoner information from NOMIS and outputs the data to feather files. This forms the backend for the bentham app which is used by prison-based intelligence analysts to search through seized media.
Run memory-intensive workloads
For example the prison network airflow pipeline runs daily and downloads and processes ~100GB of data. Each prisoner is assigned a node and edges to link the nodes are created from data such as financial transactions, prison incidents, visits, seized mobile phone data. The pipeline cannot run using standard nodes and uses a high-memory node.
Run end-to-end processing workflows involving multiple steps and dependencies
The Safety Diagnostic Tool (SDT) airflow pipeline is extremely complex and made up of 7 tasks, each with different dependencies. For example, the ‘spells-correction’ task cleans prisoner spells data in NOMIS, which is then used to fit the Violence in Prisons Estimator (VIPER) model in the ‘viper’ task. This task provides a summary of prisoners’s violence that is used in the SDT RShiny application.
Monitor the performance of workflows, identify and resolve issues
Airflow allows users to visually monitor failed tasks and receive email notifications. Once corrected, users can restart the pipeline from that task instead of restarting the entire pipeline
What is Airflow
Below are some key concepts in Airflow. What is discussed is covered in more detail in this talk.
Tasks These are the things you want to do; the building blocks of the pipeline. Let’s say I want to run a script that does some basic data processing when a specific file is created in a particular location. Once this processing is done, a second script writes a report based on the processed data. You might want to model this as a set of tasks i.e. file_created_sensor -> script_1 -> script_2.
Operator An
Operatoris a Task template. There are loads of pre-made operators to carry out common tasks such as running python (PythonOperator) or bash (BashOperator) scripts. However it is best practice to only use operators that trigger computation out of Airflow in a separate processing solution. We use a Kubernetes cluster and the KubernetesPodOperator to launch a docker container (see below).DAG (Directed Acyclic Graph) DAGs define the tasks, the order of operations, and the frequency/schedule that the pipeline is run. DAGs have a schedule interval (a cron-expression detailing when and how often to run the pipeline), and are considered “acyclic” because the sequence flow must never loop back on itself. There can be branches and joins, but no cycles. For example task A -> B -> C -> A is not allowed.
Schedule Interval This is an expression describing the start date and end date bound to the data ingested by the pipeline, and the frequency at which to run the pipeline. For example, a
@dailytask defined as 19:00:00, starting on 01-01-2022. This task would be triggered just after 18:59:59 the following day (02-01-2022) after the full day’s worth of data exists. As such, the scheduler runs the job at the end of each period.Airflow UI The Airflow UI makes it easy to monitor and troubleshoot your data pipelines. You can also use it to manually trigger your workflow.
What is Kubernetes
Kubernetes is a platform for automating the deployment, scaling, and management of containers. We use it in conjunction with Airflow to run Airflow pipelines. This means Airflow can concentrate on scheduling and monitoring the pipelines, whilst the Kubernetes cluster can concentrate on doing the heavy-lifting processing. You will not have access to the Kubernetes cluster but it’s helpful to understand the key concepts.
Container The term to describe a portable software package of code for an application along with the dependencies it needs at run time. Containers isolate software from its environment and ensure that it works uniformly regardless of underlying infrastructure (e.g. running on Windows vs. Linux). Your containers will usually contain R/python code.
Image act as a set of instructions to build a container, like a template. Public and private registries are used to store and share images such as Amazon Elastic Container Registry ECR.
Docker Software framework for building and running containers.
Cluster When you deploy Kubernetes, you get a cluster. A Kubernetes cluster consists of a set of worker machines, called nodes, that run containerized applications.
Node Kubernetes runs your workload by placing containers into Pods to run on Nodes. A node may be a virtual or physical machine, depending on the cluster. Kubernetes can create nodes with different specifications (e.g. high-memory) and force pods to run on specific nodes.
Pod a group of one or more containers with shared resources, and a specification for how to run the containers.
Airflow Environments
There are two separate Airflow environments, each with it’s own Kubernetes cluster:
There is also a sandpit environement for data engineers to test upgrades to the Airflow platform but you will not have access to this environment.
Airflow Pipeline
Within the MoJ Analytical Platform, a typical Airflow pipeline consists of the following steps (Actions inside the grey box are automated):
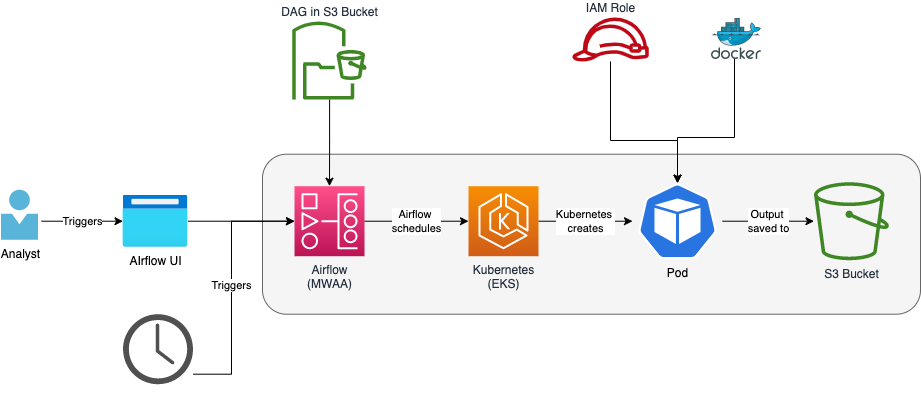
The DAG can be triggered by an analyst through the Airflow UI or through a schedule
The DAG script is stored in an AWS S3 bucket and defines a Kubernetes pod operator and an image which contains the required python/R code
The Kubernetes pod operator launches a single-container pod in a Kubernetes cluster
The pod pulls the image from the ECR registry in the Data Engineering AWS account
The pod will need permission to access various AWS resources (i.e. run an Athena query, read-write to a bucket, etc). This is achieved by assuming an Identity and Access Management (IAM) role with the relevant permissions
The output is then usually saved to an S3 bucket
The next two sections summarises the process for creating (and maintaining) the DAG, image and IAM roles. This uses two deployment pipelines which are automated using various Github actions that we have created to facilitate this process.
Image Pipeline
Note that you can skip this pipeline if you already have a working docker image saved to the Data Engineering ECR.
This deployment pipeline creates a docker image which contains the analytical code (python or R) that will be run in the dockerised task. Actions highlighted in grey are automated.
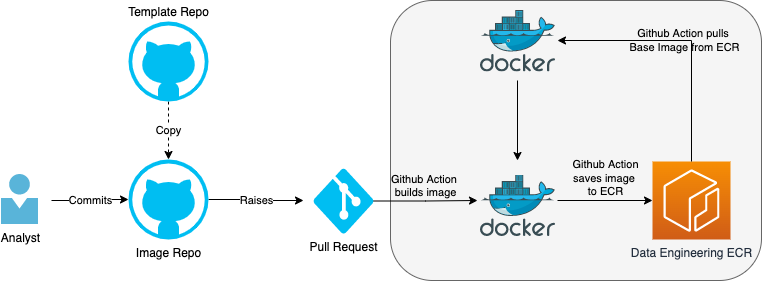
The image repo must contain the build-and-push-to-ecr Github action to push the docker image to the Data Engineering Elastic Container Registry (ECR). This can be done by:
- copying template-airflow-python for python images
- copying template-airflow-r for R images
- copying the Github action to an existing image repo
Please see Image pipeline for more details.
DAG Pipeline
This deployment pipeline creates the Directed Acyclic Graph (DAG) which defines the tasks that will be run, as well as the IAM role which the Kubernetes pod will need in order to access relevant AWS resources and services. Actions highlighted in grey are automated.
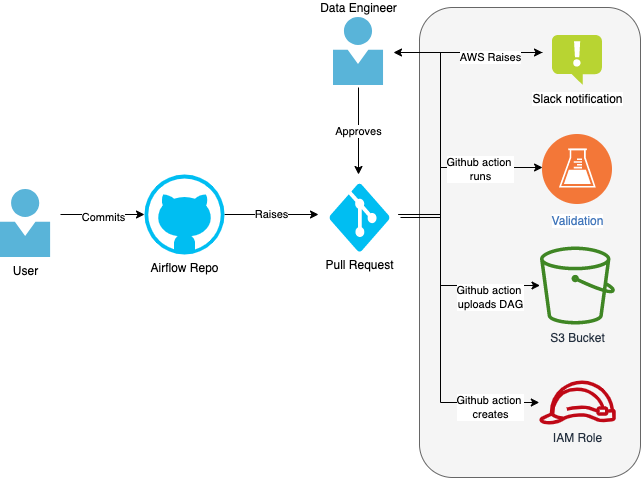
You must add the DAG and role policies to airflow following specific rules. See DAG pipeline for more details. Once you raise the PR and it is approved by data engineering, various Github actions will automatically:
- validate the DAG and policies adhere to the rules
- notify DE through a slack notification
- create/update the IAM role
- save the DAG to an S3 bucket which can be accessed by Airflow
Component Responsibilities
Since an Airflow pipeline consists of so many moving components, it is helpful to summarise everyone’s remit.
Analysts are responsible for creating/maintaining the following components:
- DAG which defines the analytical tasks that the pipeline will run
- IAM policies for the IAM Role that the Kubernetes pod will use
- Image repo and the code that will be run in the tasks
Data Engineering is responsible for maintaining the following components:
- airflow environments
- kubernetes clusters
- github actions for automating the deployment pipelines
- template image repo to base the image repo from
- user guidance
as well as approving the DAG and IAM Role PR.
When not to use an Airflow
- to trigger an Analytical Platform app (the Analytical Platform team can create cron jobs for this)