Tools for Data Processing
Data on the Analytical Platform comes in many forms (see data FAQS). We have raw and curated ‘source’ data such as Delius, Nomis, Common Platform (and much more) that typically lands onto the Analytical Platform through the hands of our Data Engineers or through users uploading data using tools like the Data Uploader. We also have derived data, which has been carefully designed and modelled by Analytics Engineers to be easier to use compared to source data.
However, often, users of data want to apply a further changes to their data to make it fit for their purposes and needs. Sometimes these changes are referred to using a variety of terminologies such as data cleaning, data manipulation, data transformation, data wrangling. Here, we describe the steps to change the data as the data processing, and the resulting data as the processed data. The processing steps could be small, such as just reducing the volume of data in a single table by aggregating values, or more complex, like combining and joining several tables and passing them through functions. But this poses the question…
What tools can I use to create and run my data processing?
There is no single choice because it depends on several factors. For example, you’ll need to consider:
- Data for Exploration or Data for Production? Is the processed data produced purely for exploration purposes, or do you want the data to be saved and used by others or a production system?
- Manual or Automated? Do you want to regularly, or routinely, generate the data via a pipeline or manually trigger your data processing steps?
- AP or Outside? Does the code for the data processing need to be sent to another team or work area, and what tools do they have access to?
Processing data manually for exploration
Below are the Analytical Platform tools typically used to manually undertake data processing during exploration. That is, you are trying stuff out and don’t need your code to be automated.
JupyterLab, RStudio or Visual Studio Code
Typically, data users on the Analytical Platform will use JupyterLab, RStudio, or Visual Studio Code to interact with and process data. There are several R or Python (or any other language using VSCode) packages you can use for this, and these tools integrate well with GitHub authentication for the Analytical Platform. So all you need to do is make sure you have access to the data itself (see database access and S3 warehouse data).
✅ Pros
- Version control through GitHub
- Data can be both structured (databases), and unstructured
- Access to many packages, extensions and coding languages (especially if using Visual Studio Code)
- Debugging through an Integrated Development Environment (IDE) such as Visual Studio Code
- Easier to migrate code to Airflow (see below) or send to others to run if they have access to same tools
❌ Cons
- Initial setup time of projects is time-consuming
- Code to run simple SQL is more complex than required on Athena workbench
Amazon Athena Console
Another option is to use the Athena Console directly on AWS through the Analytical Platform Control Panel. The Athena Console allows you to write and run SQL code directly. This is very handy when exploring data that is already in an Athena database and table.
✅ Pros
- Quick to get started as you don’t need to install anything
- Creates modular SQL script thinking needed for Create a Derived Table (see below)
❌ Cons
- SQL only - limiting how complex your processing can be
- No proper version control, makes it hard for others to replicate
Create-a-derived-table
Create-a-derived-table is an in-house developed service that brings dbt, Git, and data access controls together to allow you to deploy derived and processed tables from data available on the Analytical Platform. This extends SQL with features commonly associated with programming languages, enabling more flexible, scalable, and maintainable code. dbt can also assure the quality of your transformations through data tests, for example to check whether columns contain null values.
Processing data using an automated pipeline
Airflow
Apache Airflow is an open-source platform used to programmatically author, schedule, and monitor complex workflows and pipelines. It can be used to run scripts written in R, Python, or any other coding language. Airflow jobs are created using the airflow repository. See the user guidance page on Airflow for more information.
✅ Pros
- Well-established and good community support from AP users and wider (used in many organisations)
- Highly flexible, such as the ability to use GPUs if needed
- Data can be both structured, and unstructured
❌ Cons
- Have to set up Dockerfile and DAG
- Have to describe task order in DAG manually
- Difficult to trigger run only when underlying data has been updated - usually have to hard-code a start time
- Debugging and logging aren’t great
- Setup even for simple tasks can be complex
Create a Derived Table
Create a Derived Table also allows you to run scheduled table updates.
✅ Pros
- Processing can be triggered when underlying ‘source’ data has been updated
- Need to only know SQL and some Jinja templating
- Encourages modular, reusable SQL transformations, which promotes maintainable and scalable codebases
- Has good Git integration for version control
- Built-in testing
- Creates documentation and data lineage graphs, aiding in understanding and maintaining data pipelines.
❌ Cons
- dbt is new(ish) tool that people may not be familiar with and need to learn syntax
- Designed for SQL transformations, which can be limiting for complex logic that might require other programming languages added as macros
- Data needs to be in an Athena table already (or manually added to GitHub repo as a seed)
Example of deciding between Airflow or Create a Derived Table
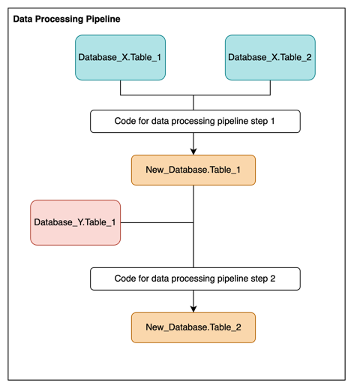
There is a request to process data from three tables across two Databases (X and Y) into a single table, so that this new, processed data can be used in an operational system. Both Databases are already in Athena on the Analytical Platform. The code for step 1 of the data processing pipeline needs to join together the two tables from Database X into a new table in a new Database. Then, the code second step (2) needs to bring in data from Database Y and link to the existing data. Below are considerations to use Create a Derived Table or Airflow for this request.
Data Structure
Because the data is in a structured format in an Athena table already, this can be achieved in both Airflow or Create a Derived Table. If the data was unstructured, the pipeline would need to use Airflow.
Complexity
Because the processing steps are just SQL code then Create a Derived Table can be used. If the processing steps involved non SQL (e.g. Python or R) code then this would require Airflow.
Upstream data
Because the processed data is to be used in an operational system, it is important that the system has access to quality, up-to-date data. Data processing pipelines created in Create a Derived Table will only be triggered after pipelines to create source tables have run. The tool is also able to recognise the dependencies between tables being deployed, and so will deploy tables as soon as upstream tables are finished, without having to wait for the rest of the deployment to occur. This means by using Create a Derived Table the data processing pipeline will not run before data in Database X and Y have been updated and passed quality checks. With Airflow, this is more difficult to achieve.
Downstream users
In general, it is best practice to make data transparent and accessible to others, unless there is a business or data protection reason not to. Create a Derived Table generates a data catalog and data lineage for users to discover processed data. It is possible to provide a basic description of data from Airflow by adding information to the Glue Catalog, but this will require bespoke code to do so.
So, Airflow or Create a Derived Table?
As the code for the data processing pipeline can be written using SQL and this processed data needs to feed into an operational system, the pipeline should only run when the upstream data is ready. As a result, this work is a good example of where Create a Derived Table should be used.
FAQ
Can I run Python or R code in Create a Derived Table?
At the moment you can not run Python or R code with Create a Derived Table. It’s something the Data Platform Services team are exploring in the future but because it requires a different compute than regular Athena queries they want to test internally to understand cost implications first.